캐시(Cache) 메모리
프로세서 속도의 발전 속도를 메모리가 따라가지 못하고, 이 간격을 메우기 위해 메모리를 효율적으로 사용하고자 하였다. 메모리를 계층적 구조로 설계했을 때 프로세서와 가까운 계층에 위치시켜 메인 메모리까지 접근하지 않고도 프로세서가 데이터를 읽어 올 수 있도록 도와주는 메모리
캐시로 들어가기 전에
다음을 가정하자
- 메인 메모리는 여러개의 균일한 page(또는 block)로 나누어져 있다.
- Byte addressing을 한다. (프로세서와 메모리가 한번에 1byte를 처리, 1word = 1byte)
- MMU 고려x
- Main Memory = 8kB
- 한개의 page에 4개의 위치(word, byte)가 존재
- Cache memory = 256B
- Main Memory의 한 page는 cache의 한 line에 저장된다.
캐시의 기본 구조
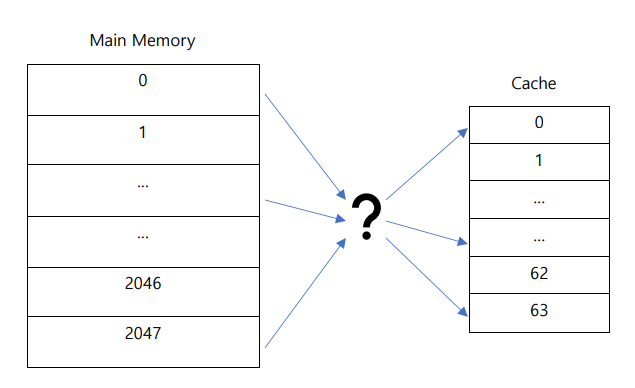
위의 가정을 바탕으로 Main memory와 Cache memory를 나타내면 다음과 같다.

메인 메모리의 크기가 8kB이고, 한 page에 4byte가 들어있으므로 \(2^{3} * 2^{10} * 2^{2} = 2^{13}\) 이고, 따라서 13bit로 메인 메모리의 모든 위치(word, byte)를 나타낼 수 있다. 13bit에서 2bit는 한 page에 들어있는 4개의 word(byte)의 위치(offset)을 나타내기 위해 사용된다. 그리고 메인 메모리에는 \(2^{3} * 2^{10} / 2^{2} = 2^{11} = 2048\)개의 page가 존재함을 계산할 수 있다.
Direct Mapping
Direct Mapping은 cache의 각 line에 규칙에 따라 정해진 데이터들만 저장하는 방식이다.
캐시 메모리의 크기가 256B이고, 한 page에 4byte가 들어있으므로, \(2^{8} / 2^{2} = 2^{6} = 64\)개의 line(page)이 존재함을 알 수 있다.
그리고 캐시의 64개의 line을 표현하기 위해선 6bit가 필요하므로, 메인 메모리의 위치를 나타내는 13bit에서 6bit는 이를 위해 사용된다. 나머지 5bit는 tag bit로 처리되는데, 캐시의 line에 접근했을 때 이 line에 있는 데이터가 진짜 프로세서가 요청한 데이터인지 확인하는데에 사용된다.
이것들을 나타내면 아래와 같다.

프로세서가 13bit 주소를 캐시로 보내면, 캐시는 6bit를 사용하여 이 주소가 캐시의 어디 line에 저장될 수 있는지 보고, 그 line의 valid bit를 확인한다. valid bit가 유효하면(1이면) tag를 비교하여 같으면 hit로 처리하여 그 위치의 데이터를 프로세서에게 보내고, 다르다면 miss로 처리하여 메인 메모리에서 프로세서가 요청한 데이터를 읽어와 cache의 해당 line에 저장하는데, line에 데이터가 이미 존재한다면 그 데이터를 내보내고 저장한다.
valid bit는 cache의 해당 line이 유효한지 알려주는 역할을 한다. 0이라면 해당 line은 유효하지 않은 상태라는 뜻이고, miss를 발생시켜 메인 메모리에서 데이터를 읽어와 저장하고 valid bit를 1로 바꾼다.

Direct Mapping은 메인 메모리의 특정 page가 캐시의 어디에 있는지, 있을지 알기 쉽다. 각 주소마다 들어갈 수 있는 캐시의 line이 정해져있기 때문이다. 주소를 표현하는 13bit중 6bit가 캐시의 line을 구하는데 사용하므로, 이 6bit를 \(2^{6} = 64\)로 나눈 나머지와 같은 값을 가지는 캐시의 line에 해당 주소의 데이터가 저장되어 있을 것으로 추측할 수 있다. 따라서 캐시에서 데이터를 쉽게 찾을 수 있다는 장점이 있다.
앞의 예시에선 캐시의 line이 64개이므로 위의 그림과 같이 각 메모리의 page가 들어갈 수 있는 line이 고정된다. 메인 메모리의 0, 64, 128, ..., 1024번 page는 모두 캐시의 0번 line에 저장될 수 있는 후보들이다. 0번 page가 캐시에 존재하는데 64번 page를 요청받으면 캐시는 0번 page에 대한 데이터를 버리고 64번 page에 대한 데이터를 메인 메모리에서 읽어와 저장한다.
따라서 Direct Mapping은 특별한 교체 알고리즘이 필요하지 않다. 같은 위치에 들어갈 데이터들이 정해져 있기 때문에, 서로 밀어내며 교체하면 되기 때문이다. 하지만 이런 방법은 0, 64, 128, ..., 1024번 page에 연속하여 접근할 경우, 캐시의 0번 line에서 잦은 교체가 일어나고 비효율적이라는 단점이 있다.
위 그림을 참고하여 보면 이진수로 표현했을 때, 같은 행은 같은 line 값을 가지고, 같은 열은 같은 tag값을 가진다.
0~63은 tag 0, 64~127은 tag 1, ...
0, 64, 128, ...은 line 1, 1, 65, 129은 line 2, ...
따라서 주어진 페이지의 주소를 캐시 line 수로 나누면 해당 page의 tag, line 값을 알 수 있다.
ex) 191 = 64 * 2 + 63 --> tag = 2, line = 63
이렇게 64개 line과 32개 tag를 사용하면 2048개의 메인 메모리 주소(위치) 중에서 하나를 특정할 수 있다.
Direct Mapping의 전체적인 과정은 아래와 같다.

Associative Mapping
Associative Mapping은 Direct Mapping에 비해 개념은 비교적 단순하다. Direct Mapping이 메인 메모리의 데이터를 특정 위치를 정해 저장했다면, Associative Mapping은 모든 주소의 데이터는 캐시의 어떤한 line에도 들어갈 수 있기 때문이다.
앞선 예시와 동일하게 주소를 표현하는데 13bit가 사용되고, 이중 2bit는 offset을 표현하는데 사용된다. 그리고 나머지 11bit는 모두 tag를 표현한다. Direct Mapping과 다르게 캐시의 line을 계산하지 않기 때문에 line(index) bit는 필요가 없다.
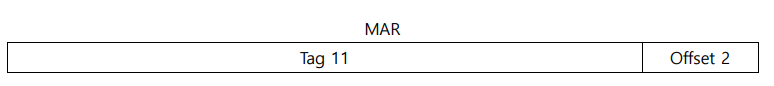
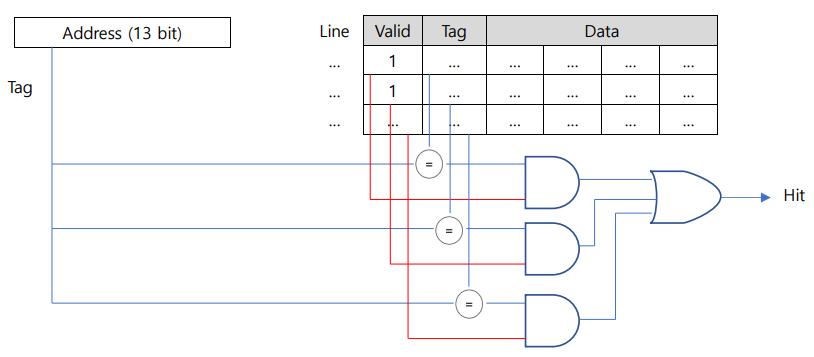
캐시에 접근할 때는 valid bit와 tag만 비교하여 hit, miss를 판단한다.
Associativie Mapping은 Direct Mapping보다는 아이디어가 간단하지만, 구현하기엔 하드웨어적으로 부담이 더 크다. Associative Mapping은 데이터가 캐시에 저장되는 정해진 위치가 없기 때문에, 특정 데이터를 찾으려면 캐시의 모든 line을 비교해야 하기 때문이다. 모든 line을 비교하려면 parallel하게 비교가 가능해야 하고, 이를 하드웨어로 구현하게 되면, 많은 comparator가 필요하고 비용이 증가한다.
Associative Mapping은 구현하기 비싸긴 하지만, 매우 빠르게 동작한다. 따라서 속도가 중요한 곳에 사용되기도 하는데, TLB가 Associative Mapping을 이용해 구현되기도 한다.
Associative Mapping은 정해진 규칙에 따라 캐시에 데이터를 저장하지 않기 때문에, 캐시가 꽉찼을 때 데이터를 더 넣으려면 기존에 있던 데이터 중에서 내보내야할 데이터를 선택해야 한다. 이런 데이터를 선택하는 것을 교체 알고리즘이라고 하고, FIFO, LRU, LFU 등 다양한 알고리즘이 존재한다. 이에 대한 내용은 글 뒷부분에 있다.
Set Associative Mapping
Set Associative Mapping은 Direct Mapping과 Associative Mapping의 개념은 함께 사용한 것이다.
Direct Mapping처럼 어떤 데이터가 들어갈 수 있는 장소(set)가 정해져 있고, 이 장소 내부에선
장소의 크기(way)에 맞게 Associative Mapping처럼 빈 공간이 있으면 아무데나 들어가 저장된다.
set에 존재하는 way의 수에 따라 n-way Set Associative Mapping이라고 한다.
아래는 2-way의 경우를 나타낸 그림이다.
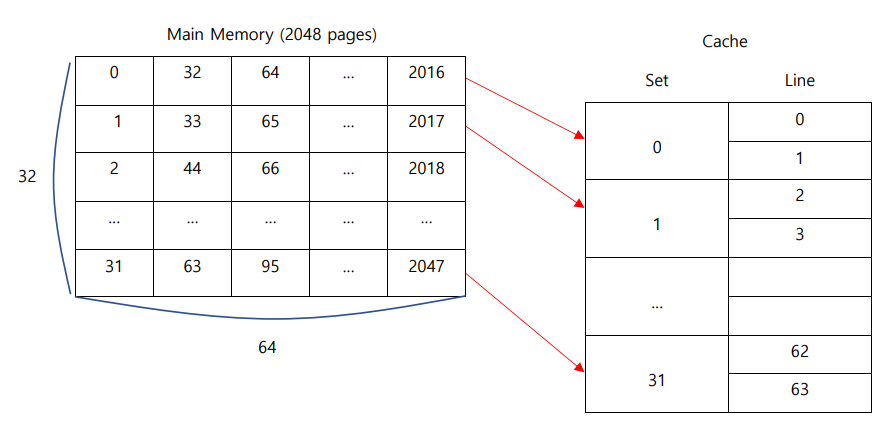
2-way이기 때문에, 64개의 line이 2개씩 32개의 set으로 묶였다. 따라서 캐시의 32개의 set을 나태낼 수 있도록 5bit가 필요하다. 앞선 예시와 동일하게 offset을 표현하는데 2bit가 필요하므로, 13bit 중 나머지 6bit가 tag를 표현한다.

데이터가 들어갈 set은 Direct Mapping처럼 나머지 연산을 사용하여 구한다. 예를 들어, page 33은 캐시 line의 수인 32로 나누면 나머지가 1이기 때문에, 1번 set에 들어가야 한다. 각 set에는 2개의 공간(way)이 있고, 이 공간 중 빈 곳에 33번 page의 데이터가 들어간다.
이렇듯, Set Associative Mapping은 Direct Mapping의 빈번한 데이터 교체 문제를 완화시키고, 쉬운 데이터 위치 탐색의 장점을 살리는 한편, Associative Mapping의 유연한 데이터 삽입의 장점도 적용한 방법이다.
Set Associative 관점에서 Direct Mapping은 one-way Set Associative Mapping이라고 볼 수 있고, Associative Mapping은 그 특징을 좀 더 살리기 위해 Fully Associative Mapping이라고 부르기도 한다.
Replacement Algorighms
캐시 내의 어떤 데이터를 내보낼지에 대한 교체 알고리즘은 Direct Mapping에서는 필요 없지만 Fully Associative Mapping, Set Associative Mapping에서는 필요하다.
1. FIFO(First-in-first-out)
선입선출
캐시 내에 가장 먼저 들어왔던 데이터를 내보내는 방법
round-robin과 circular buffer를 사용하여 구현하기 간단
2. LFU(Least Frequenty Used)
가장 적게 사용된 데이터를 내보내는 방법
데이터가 사용된 횟수를 저장할 수 있어야 하기 때문에 구현이 까다로움
3. LRU(Least Recently Used)
가장 오래전에 참조된 데이터를 내보내는 방법
temporal locality를 잘 반영한다
이외에도 여러 알고리즘이 있고, 각 알고리즘마다 특징이 있기 때문에 적절한 알고리즘 선택 필요
3C's
캐시의 세가지 miss 요인
1. Compulsory
강제적임, 캐시의 특정 line을 처음 접근하는 경우, 아무것도 없기 때문에 무조건 발생
2. Capacity
용량, 필요한 데이터의 크기가 캐시 전체 용량을 초과하는 경우 발생
3. Conflict
충돌, 캐시의 같은 위치(set)에 허용된 것(way)보다 많은 개수의 데이터가 들어가려고 하는 경우 발생
추가로 4번째 C라고도 하는 Coherence(Invalidation, Communication) miss도 있다.
4. Coherence
멀티코어 환경에서 서로 다른 캐시가 여러 프로세서에 존재하는 환경에서 발생
같은 데이터를 공유하고 있는 상태에서 다른 프로세서가 그 데이터를 변경하면 나머지 캐시들은 그 데이터를 유효하지 않는 상태(invalidate)로 바꾸는데, 이 invalidate한 데이터에 접근하여 발생
기타
캐시에 page 단위로 데이터를 저장하는 이유는 공간적 지역성(spacial locality) 때문이다. 프로그램은 실행될 때, 이전에 접근했던 위치와 인접한 위치의 데이터에 높은 확률로 접근하는 성질이 있어서 캐시에 데이터를 읽어올 때, 하나씩이 아닌 근처의 데이터까지 뭉텅이로 가져온다.
캐시의 사이즈, line 사이즈, way의 수, write policy, replacement algorigthms 등 캐시의 구조를 설계, 결정할 때 고려해야할 요인들이 많다. 각각 trade off들이 존재하기 때문에, 자신이 필요에 따라 캐시를 설계, 결정할 수 있어야 한다.
캐시 동작은 cache simulator코드를 동작시키면서 보면 더 쉽게 이해할 수 있었다. Github에 cache simulator를 검색하면 몇몇 프로젝트들이 나온다. 그대로 동작시켜도 되지만, 이 중 하나를 골라 코드를 조금씩 수정하면서 캐시의 변화를 관찰하며 동작 시켜봤던 것이 도움이 많이 되었다.
'컴퓨터구조' 카테고리의 다른 글
| 캐시 일관성(cache coherence)과 프로토콜 (0) | 2023.02.07 |
|---|---|
| 멀티코어의 등장 배경 (0) | 2023.01.12 |
| 컴퓨터 구조를 시작하면서 - A New Golden Age for Computer Architecture (0) | 2022.10.19 |